Model tools
On this page
Model mixin
Utilities for fit, inference, and evaluation of classifiers.
- class simba.mixins.train_model_mixin.TrainModelMixin[source]
Train model methods
- bout_train_test_splitter(x_df, y_df, test_size)[source]
Helper to split train and test based on annotated bouts.

- Parameters
x_df (pd.DataFrame) – Features
y_df (pd.Series) – Target
test_size (float) – Size of test as ratio of all annotated bouts (e.g.,
0.2).
- Returns
Size-4 tuple with DataFrames of Series representing, (i) Features for training, (ii) Features for testing, (iii) Target for training, (iv) Target for testing.
- Return type
Tuple[pd.DataFrame, pd.DataFrame, pd.Series, pd.Series]
- Examples
>>> x = pd.DataFrame(data=[[11, 23, 12], [87, 65, 76], [23, 73, 27], [10, 29, 2], [12, 32, 42], [32, 73, 2], [21, 83, 98], [98, 1, 1]]) >>> y = pd.Series([0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]) >>> x_train, x_test, y_train, y_test = TrainModelMixin().bout_train_test_splitter(x_df=x, y_df=y, test_size=0.5)
- calc_learning_curve(x_y_df, clf_name, shuffle_splits, dataset_splits, tt_size, rf_clf, save_dir, save_file_no=None, multiclass=False, scoring='f1', plot=True)[source]
Helper to compute random forest learning curves with cross-validation.
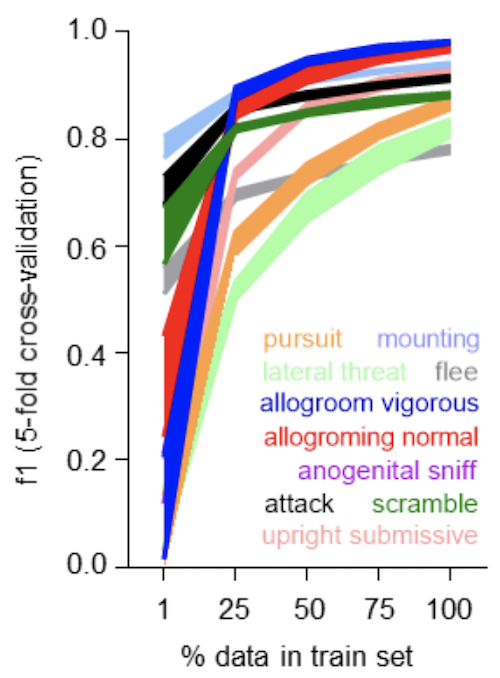
- Parameters
x_y_df (pd.DataFrame) – Dataframe holding features and target.
clf_name (str) – Name of the classifier
shuffle_splits (int) – Number of cross-validation datasets at each data split.
dataset_splits (int) – Number of data splits.
tt_size (float) – The size of the test set as a ratio of the dataset. E.g., 0.2.
rf_clf (RandomForestClassifier) – A sklearn RandomForestClassifier object.
save_dir (str) – Directory where to save output in csv file format.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
multiclass (bool) – If True, then target consist of several categories [0, 1, 2 …] and scoring becomes
None. If False, then scoringf1.scoring (Optional[str]) – The score of the models to present. Default: ‘f1’.
plot (Optional[bool]) – If True, creates plot with the train fraction size on x and
scoringon y.
- Returns
None. Results are stored in
save_dir.
- calc_permutation_importance(x_test, y_test, clf, feature_names, clf_name, save_dir=None, save_file_no=None, plot=True, n_repeats=10)[source]
Computes feature permutation importance scores.
- Parameters
x_test (np.ndarray) – 2d feature test data of shape len(frames) x len(features)
y_test (np.ndarray) – 2d feature target test data of shape len(frames) x 1
clf (RandomForestClassifier) – random forest classifier object
feature_names (List[str]) – Names of features in x_test
clf_name (str) – Name of classifier in y_test.
save_dir (str) – Directory where to save results in CSV format. If None, then returns the dataframe and the plot (if plot
plot (Optional[bool]) – If True, creates bar plot chart and saves in same directory as the CSV file.
save_file_no (Optional[int]) – If permutation importance calculation is part of a grid search, provide integer identifier representing the model in the grid serach sequence. This will be used as suffix in output filename.
- Returns
Either non or a Tuple with the dataframe and the plot. A CSV file representing the permutation importances is stored in
save_dirif save_dir is passed.
- calc_pr_curve(rf_clf, x_df, y_df, clf_name, save_dir, multiclass=False, plot=True, classifier_map=None, save_file_no=None)[source]
Compute random forest precision-recall curve.

- Parameters
rf_clf (RandomForestClassifier) – sklearn RandomForestClassifier object.
x_df (pd.DataFrame) – Pandas dataframe holding test features.
y_df (pd.DataFrame) – Pandas dataframe holding test target.
clf_name (str) – Classifier name.
save_dir (str) – Directory where to save output in csv file format.
multiclass (bool) – If the classifier is a multi-classifier. Default: False.
plot (Optional[bool]) – If True, creates and saves line plot PR curve in the same lication as the output CSV file.
classifier_map (Dict[int, str]) – If multiclass, dictionary mapping integers to classifier names.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
- Returns
None. Results are stored in save_dir`.
- check_df_dataset_integrity(df, file_name, logs_path)[source]
Helper to check for non-numerical np.inf, -np.inf, NaN, None in a single dataframe. :param pd.DataFrame x_df: Features :raise NoDataError: If data contains np.inf, -np.inf, None.
- check_raw_dataset_integrity(df, logs_path)[source]
Helper to check column-wise NaNs in raw input data for fitting model.
:param pd.DataFrame df :param str logs_path: The logs directory of the SimBA project :raise FaultyTrainingSetError: When the dataset contains NaNs
- check_sampled_dataset_integrity(x_df, y_df)[source]
Helper to check for non-numerical entries post data sampling
- Parameters
x_df (pd.DataFrame) – Features
y_df (pd.DataFrame) – Target
- Raises
FaultyTrainingSetError – Training or testing data sets contain non-numerical values
- check_validity_of_meta_files(data_df, meta_file_paths)[source]
Validate a collection of classifier hyper-parameter meta (config) files prior to model training.
- Parameters
data_df (pd.DataFrame) – Annotated feature dataframe used to sanity-check sampling ratios against the number of behavior-present and behavior-absent frames.
meta_file_paths (List[Union[str, os.PathLike]]) – Paths to the classifier meta (config) files to validate.
- Returns
Dictionary mapping the index of each valid meta file to its sanitized parameter dictionary.
- Return type
- Example
>>> meta_dicts = TrainModelMixin().check_validity_of_meta_files(data_df=data_df, meta_file_paths=['project_folder/configs/Attack_meta.csv'])
- clf_define(n_estimators=2000, max_depth=None, max_features='sqrt', n_jobs=- 1, criterion='gini', min_samples_leaf=1, bootstrap=True, verbose=1, class_weight=None, cuda=False)[source]
Instantiate an un-fitted random forest classifier object from the passed hyper-parameters.
Note
If
cuda=Trueand the cuml library is available, a GPU-acceleratedcuml.ensemble.RandomForestClassifieris returned instead (note: cuml capsmax_depthat 32, so larger orNonevalues are clamped to 32).See also
To fit the returned object, see
simba.mixins.train_model_mixin.TrainModelMixin.clf_fit()- Parameters
n_estimators (Optional[int]) – Number of trees in the forest. Default: 2000.
max_depth (Optional[int]) – Maximum depth of each tree. If None, nodes expand until pure (clamped to 32 when
cuda=True). Default: None.max_features (Optional[Union[str, int]]) – Number of features to consider at each split (e.g.
'sqrt','log2', an int, or None for all features). Default: ‘sqrt’.n_jobs (Optional[int]) – Number of parallel jobs used to fit and predict (sklearn only).
-1uses all cores. Default: -1.criterion (Optional[str]) – Split-quality function, e.g.
'gini'or'entropy'(sklearn only). Default: ‘gini’.min_samples_leaf (Optional[int]) – Minimum number of samples required at a leaf node. Default: 1.
bootstrap (Optional[bool]) – If True, bootstrap samples are used when building trees. Default: True.
verbose (Optional[int]) – Verbosity level during fitting. Default: 1.
class_weight (Optional[dict]) – Weights associated with classes (sklearn only), e.g.
{0: 1, 1: 2}. If None, all classes are weighted equally. Default: None.cuda (Optional[bool]) – If True, return a GPU-accelerated cuml random forest instead of the sklearn classifier. Requires the cuml library. Default: False.
- Returns
An un-fitted random forest classifier object (sklearn or cuml).
- Return type
Union[RandomForestClassifier, cuRF]
- Example
>>> clf = TrainModelMixin().clf_define(n_estimators=2000, criterion='entropy', max_features='sqrt')
- clf_fit(clf, x_df, y_df, selected_feature_names=None, verbose=False)[source]
Helper to fit clf model.
EXPECTED RUNTIMES
FEATURE COUNT
OBSERVATION COUNT
GPU TIME (S)
CPU TIME (S)
500
1000
9.7055
3.6682
500
10000
14.1444
18.6429
500
100000
74.8791
400.252
750
1000
7.0187
4.0107
750
10000
14.9369
22.482
750
100000
87.2037
449.0292
1000
1000
8.3954
3.9517
1000
10000
17.4793
25.5511
1000
100000
100.3192
515.217
MAX DEPTH: 32
ESTIMATORS: 2k
CPU: 32 cores
NVIDIA GeForce RTX 4070
See also
To define a cuml/sklearn object, see
simba.mixins.train_model_mixin.TrainModelMixin.clf_define()- Parameters
clf – Un-fitted random forest classifier object, either from sklearn or cuml.
x_df (pd.DataFrame) – Pandas dataframe with features.
y_df (pd.DataFrame) – Pandas dataframe/Series with target
selected_feature_names (Optional[List[str]]) – Optional subset of feature column names from
x_dfto fit on. If None, fits on all features. Default: None.
- Returns
Fitted random forest classifier object
- Return type
RandomForestClassifier
- clf_predict_proba(clf, x_df, multiclass=False, model_name=None, data_path=None, verbose=False)[source]
Helper to predict class probabilities using a fitted random forest classifier.
Computes prediction probabilities for binary or multiclass classification using either scikit-learn or cuML RandomForestClassifier. For binary classifiers, returns the probability of the positive class (class 1). For multiclass classifiers, returns probabilities for all classes.
EXPECTED RUNTIMES
OBSERVATION COUNT
GPU TIME (S)
CPU TIME (S)
100_000
1.5299
4.0823
500_000
2.8537
24.9888
1_000_000
9.2034
51.5734
1_500_000
23.548
83.1209
2_000_000
50.6484
131.5
CLF X 10k obs / 750 features
MAX DEPTH: 32
ESTIMATORS: 2k
CPU: 32 cores
NVIDIA GeForce RTX 4070
See also
To fit a classifier, see
simba.mixins.train_model_mixin.TrainModelMixin.clf_fit()To define a classifier, seesimba.mixins.train_model_mixin.TrainModelMixin.clf_define()- Parameters
clf (Union[RandomForestClassifier, cuRF]) – Fitted random forest classifier object from sklearn or cuml.
x_df (Union[pd.DataFrame, np.ndarray]) – Features for data to predict. DataFrame or array of shape (n_samples, n_features).
multiclass (bool) – If True, the classifier predicts more than 2 classes. If False, binary classifier (default: False).
model_name (Optional[str]) – Name of the model for error messages and logging. Default: None.
data_path (Optional[Union[str, os.PathLike]]) – Path to the data file being processed, used in error messages. Default: None.
verbose (bool) – If True, print inference progress and timing information. Default: False.
- Return np.ndarray
Prediction probabilities. For binary classifiers: 1D array of shape (n_samples,) with probability of positive class. For multiclass: 2D array of shape (n_samples, n_classes) with probabilities for each class.
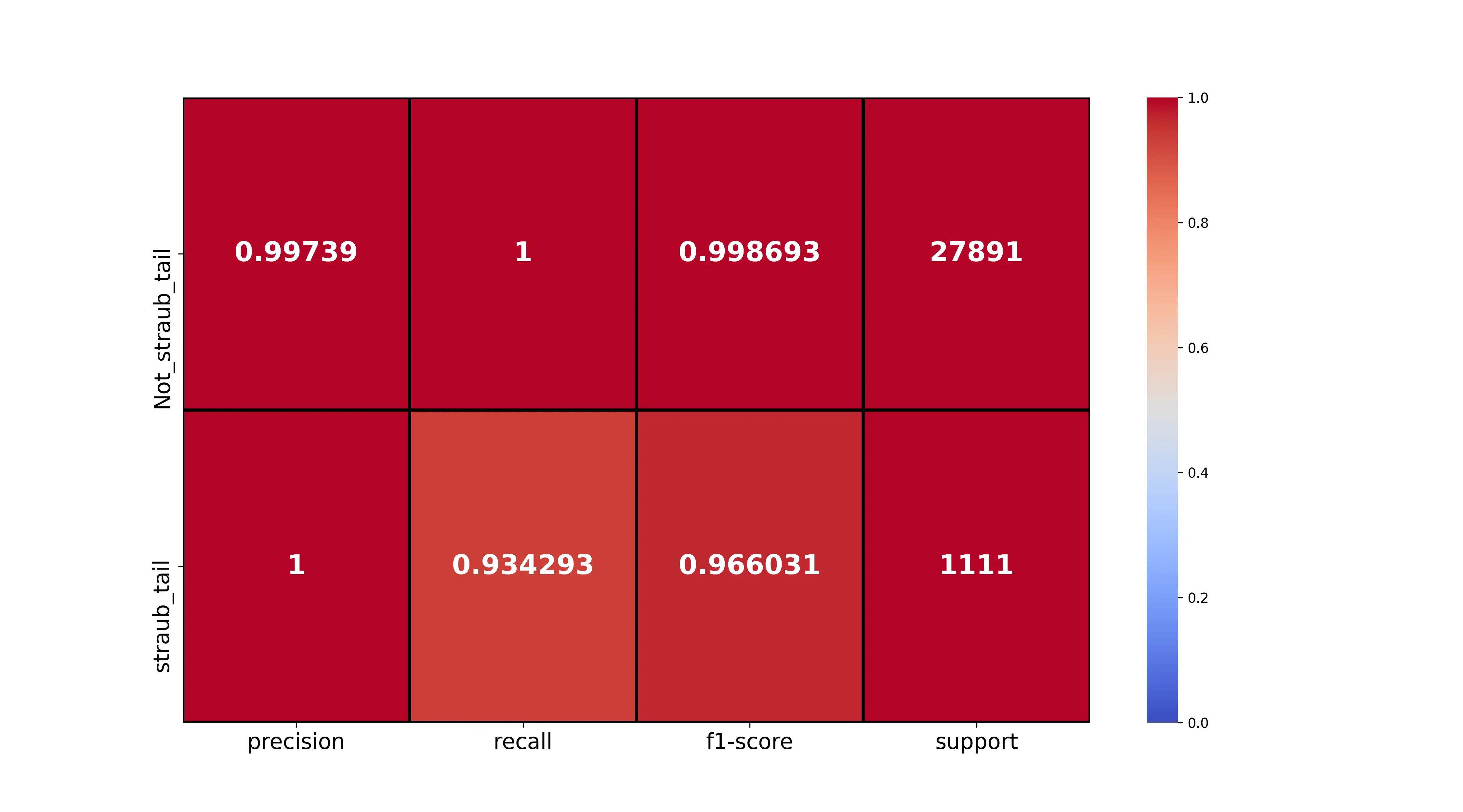
- create_clf_report(rf_clf, x_df, y_df, class_names, save_dir, digits=4, clf_name=None, img_size=(2500, 4500), cmap='coolwarm', threshold=0.5, svg=False, save_file_no=None, dpi=300)[source]
Create classifier truth table report.
Generates a classification report heatmap visualization showing precision, recall, F1-score, and support for each class. The report is displayed as a heatmap with annotations showing metric values. Predictions are made using the provided threshold to convert probabilities to binary predictions.
See also

- Parameters
rf_clf (Union[RandomForestClassifier, cuRF]) – sklearn RandomForestClassifier or cuRF object.
x_df (pd.DataFrame) – DataFrame holding test features. Must match the feature set used for training.
y_df (pd.DataFrame) – DataFrame holding test target values. Should be binary (0/1) for binary classification.
class_names (List[str]) – List of class names. E.g., [‘Attack absent’, ‘Attack present’]. Must match the order of classes in the classifier.
save_dir (Union[str, os.PathLike]) – Directory where to save the classification report image.
digits (Optional[int]) – Number of decimal places in the classification report metrics. Default: 4.
clf_name (Optional[str]) – Name of the classifier. If not None, used in the output filename. If None, uses
class_names[1].img_size (Tuple[int, int]) – Size of the output image in pixels (width, height). Default: (2500, 4500).
cmap (str) – Colormap palette for the heatmap. Default: “coolwarm” (blue to red).
threshold (float) – Classification threshold for converting probabilities to binary predictions. Values above threshold become 1, below become 0. Default: 0.5.
svg (bool) – If True, save as SVG format. If False (default), save as PNG format.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. Used in filename generation. If None, the classifier is not part of a grid search.
dpi (int) – Resolution (dots per inch) for the output image. Default: 300.
- Returns
None. Classification report image is saved to
save_dir.
- create_example_dt(rf_clf, clf_name, feature_names, class_names, save_dir, tree_id=3, save_file_no=None)[source]
Helper to produce visualization of random forest decision tree using graphviz.
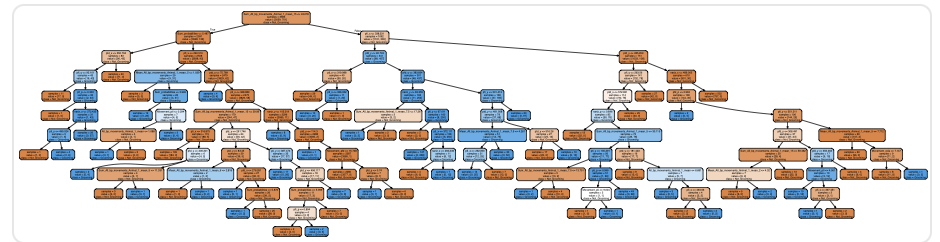
Note
- Parameters
rf_clf (RandomForestClassifier) – sklearn RandomForestClassifier object.
clf_name (str) – Classifier name.
feature_names (List[str]) – List of feature names.
class_names (List[str]) – List of classes. E.g., [‘Attack absent’, ‘Attack present’]
save_dir (str) – Directory where to save output in csv file format.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
- create_meta_data_csv_training_multiple_models(meta_data, clf_name, save_dir, save_file_no=None)[source]
- create_meta_data_csv_training_one_model(meta_data_lst, clf_name, save_dir)[source]
Helper to save single model meta data (hyperparameters, sampling settings etc.) from list format into SimBA compatible CSV config file.
- create_shap_log(rf_clf, x, y, x_names, clf_name, cnt_present, cnt_absent, verbose=True, plot=True, save_it=100, save_dir=None, save_file_suffix=None)[source]
Compute SHAP values for a random forest classifier. This method computes SHAP (SHapley Additive exPlanations) values for a given random forest classifier. The SHAP value for feature ‘i’ in the context of a prediction ‘f’ and input ‘x’ is calculated using the following formula:
\[\phi_i(f, x) = \sum_{S \subseteq F \setminus {i}} \frac{|S|!(|F| - |S| - 1)!}{|F|!} (f_{S \cup {i}}(x_{S \cup {i}}) - f_S(x_S))\]Note
Documentation Uses TreeSHAP Documentation

See also
For multicore solution, see
create_shap_log_mp()For GPU method, seecreate_shap_log()- Parameters
rf_clf (RandomForestClassifier) – sklearn random forest classifier
x (Union[pd.DataFrame, np.ndarray]) – Test features.
y (Union[pd.DataFrame, pd.Series, np.ndarray]) – Test target.
x_names (List[str]) – Feature names.
clf_name (str) – Classifier name.
cnt_present (int) – Number of behavior-present frames to calculate SHAP values for.
cnt_absent (int) – Number of behavior-absent frames to calculate SHAP values for.
save_it (int) – Save iteration cadence. If None, then only saves at completion.
save_dir (str) – Optional directory where to save output in csv file format. If None, the data is returned.
save_file_suffix (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
- Example
>>> from simba.mixins.train_model_mixin import TrainModelMixin >>> x_cols = list(pd.read_csv('/Users/simon/Desktop/envs/simba/simba/tests/data/sample_data/shap_test.csv', index_col=0).columns) >>> x = pd.DataFrame(np.random.randint(0, 500, (9000, len(x_cols))), columns=x_cols) >>> y = pd.Series(np.random.randint(0, 2, (9000,))) >>> rf_clf = TrainModelMixin().clf_define(n_estimators=100) >>> rf_clf = TrainModelMixin().clf_fit(clf=rf_clf, x_df=x, y_df=y) >>> feature_names = [str(x) for x in list(x.columns)] >>> TrainModelMixin.create_shap_log(rf_clf=rf_clf, x=x, y=y, x_names=feature_names, clf_name='test', save_it=10, cnt_present=50, cnt_absent=50, plot=True, save_dir=r'/Users/simon/Desktop/feltz')
- create_shap_log_concurrent_mp(rf_clf, x, y, x_names, clf_name, cnt_present, cnt_absent, core_cnt=- 1, chunk_size=100, verbose=True, save_dir=None, save_file_suffix=None, plot=False)[source]
Compute SHAP values using multiprocessing.
See also
- Documentation
For single-core solution, see
create_shap_log()For GPU method, seecreate_shap_log()For multiprocassing imap method (reliably runs on Windows and Mac), seecreate_shap_log_mp()
- Parameters
rf_clf (Union[RandomForestClassifier, str, os.PathLike]) – Fitted sklearn random forest classifier, or pat to fitted, pickled sklearn random forest classifier.
x (Union[pd.DataFrame, np.ndarray]) – Test features.
y_df (Union[pd.DataFrame, pd.Series, np.ndarray]) – Test target.
x_names (List[str]) – Feature names.
clf_name (str) – Classifier name.
cnt_present (int) – Number of behavior-present frames to calculate SHAP values for.
cnt_absent (int) – Number of behavior-absent frames to calculate SHAP values for.
chunk_size (int) – How many observations to process in each chunk. Increase value for faster processing if your memory allows.
verbose (bool) – If True, prints progress.
save_dir (Optional[Union[str, os.PathLike]]) – Optional directory where to store the results. If None, then the results are returned.
save_file_suffix (Optional[int]) – Optional suffix to add to the shap output filenames. Useful for gridsearches and multiple shap data output files are to-be stored in the same save_dir.
plot (bool) – If True, create SHAP aggregation and plots.
- Example
>>> CONFIG_PATH = r"C:/troubleshooting/mitra/project_folder/project_config.ini" >>> RF_PATH = r"C:/troubleshooting/mitra/models/validations/straub_tail_5_new/straub_tail_5.sav" >>> DATA_PATH = r"C:/troubleshooting/mitra/project_folder/csv/targets_inserted/new_straub/appended/501_MA142_Gi_CNO_0514.csv" >>> config = ConfigReader(config_path=CONFIG_PATH) >>> df = read_df(file_path=DATA_PATH, file_type='csv') >>> y = df['straub_tail'] >>> x = df.drop(['immobility', 'rearing', 'grooming', 'circling', 'shaking', 'lay-on-belly', 'straub_tail'], axis=1) >>> x = x.drop(config.bp_col_names, axis=1) >>> TrainModelMixin.create_shap_log_concurrent_mp(rf_clf=RF_PATH, x=x, y=y, x_names=list(x.columns), clf_name='straub_tail', cnt_absent=100, cnt_present=10, core_cnt=10)
- create_shap_log_mp(rf_clf, x, y, x_names, clf_name, cnt_present, cnt_absent, core_cnt=- 1, chunk_size=100, verbose=True, save_dir=None, save_file_suffix=None, plot=False)[source]
Compute SHAP values using multiprocessing.
See also
- Documentation
For single-core solution, see
create_shap_log()For GPU method, seecreate_shap_log()For multiprocassing concurrent futures method (should be more reliable on Linux distros), seecreate_shap_log_concurrent_mp()
- Parameters
rf_clf (RandomForestClassifier) – Fitted sklearn random forest classifier
x (Union[pd.DataFrame, np.ndarray]) – Test features.
y_df (Union[pd.DataFrame, pd.Series, np.ndarray]) – Test target.
x_names (List[str]) – Feature names.
clf_name (str) – Classifier name.
cnt_present (int) – Number of behavior-present frames to calculate SHAP values for.
cnt_absent (int) – Number of behavior-absent frames to calculate SHAP values for.
chunk_size (int) – How many observations to process in each chunk. Increase value for faster processing if your memory allows.
verbose (bool) – If True, prints progress.
save_dir (Optional[Union[str, os.PathLike]]) – Optional directory where to store the results. If None, then the results are returned.
save_file_suffix (Optional[int]) – Optional suffix to add to the shap output filenames. Useful for gridsearches and multiple shap data output files are to-be stored in the same save_dir.
plot (bool) – If True, create SHAP aggregation and plots.
- Example
>>> from simba.mixins.train_model_mixin import TrainModelMixin >>> x_cols = list(pd.read_csv('/Users/simon/Desktop/envs/simba/simba/tests/data/sample_data/shap_test.csv', index_col=0).columns) >>> x = pd.DataFrame(np.random.randint(0, 500, (9000, len(x_cols))), columns=x_cols) >>> y = pd.Series(np.random.randint(0, 2, (9000,)))
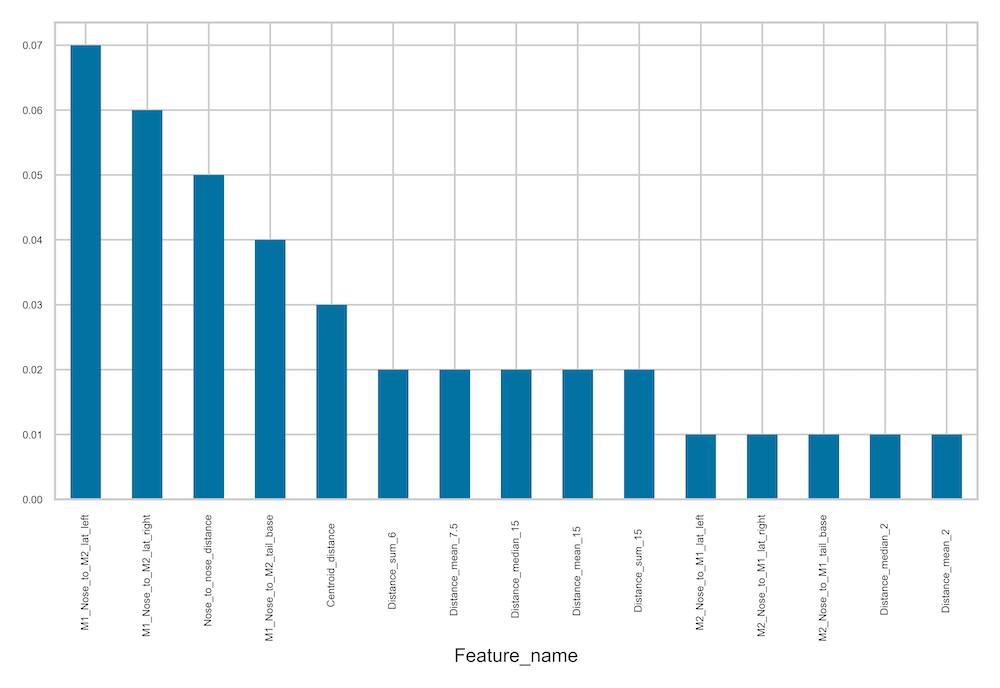
- create_x_importance_bar_chart(rf_clf, x_names, clf_name, save_dir, n_bars, palette='hot', save_file_no=None)[source]
Helper to create a bar chart displaying the top N gini or entropy feature importance scores.
See also
- Parameters
rf_clf (RandomForestClassifier) – sklearn RandomForestClassifier object.
x_names (List[str]) – Names of features.
clf_name (str) – Name of classifier.
save_dir (str) – Directory where to save output in csv file format.
n_bars (int) – Number of bars in the plot.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search
- Returns
None. Results are stored in save_dir`.
- create_x_importance_log(rf_clf, x_names, clf_name, precision=25, sort_ascending=False, verbose=True, save_dir=None, save_file_no=None)[source]
Compute gini / entropy based feature importance scores.
Calculates mean and standard deviation of feature importances across all trees in the RandomForestClassifier. Results are sorted by mean importance (descending by default) and can be saved to CSV or returned as a DataFrame.
Note
See also
To plot gini / entropy based feature importance scores, see
create_x_importance_bar_chart()- Parameters
rf_clf (Union[RandomForestClassifier, cuRF]) – sklearn RandomForestClassifier or cuRF object.
x_names (List[str]) – Names of features. Must match the number of features in the classifier.
clf_name (str) – Name of classifier. Used in output filename if
save_diris provided.precision (int) – Number of decimal places for rounding feature importance values. Default: 25.
sort_ascending (bool) – If True, sort features by importance in ascending order. If False (default), sort in descending order.
verbose (bool) – If True (default), print progress messages. If False, suppress output.
save_dir (Optional[str]) – Directory where to save output in CSV file format. If None, then returns the DataFrame instead of saving.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. Used in filename generation. If None, the classifier is not part of a grid search.
- Return Union[None, pd.DataFrame]
If
save_diris provided, returns None and saves CSV file. Ifsave_diris None, returns DataFrame with columns: ‘FEATURE’, ‘FEATURE_IMPORTANCE_MEAN’, ‘FEATURE_IMPORTANCE_STDEV’.
- cuml_rf_x_importances(nodes, n_features)[source]
Method for computing feature importance’s from cuml RF object.
From szchixy.
- static define_scaler(scaler_name)[source]
Instantiate an un-fitted sklearn scaler object from a scaler name.
See also
To fit the returned scaler, see
simba.mixins.train_model_mixin.TrainModelMixin.fit_scaler(). To transform data with a fitted scaler, seesimba.mixins.train_model_mixin.TrainModelMixin.scaler_transform().- Parameters
scaler_name (Literal["min-max", "standard", "quantile"]) – Name of the scaler to instantiate (case-insensitive).
- Raises
InvalidInputError – If
scaler_nameis not one of the accepted options.- Returns
An un-fitted sklearn scaler object.
- Return type
Union[MinMaxScaler, StandardScaler, QuantileTransformer]
- Example
>>> TrainModelMixin.define_scaler(scaler_name='min-max')
- define_tree_explainer(clf, data=None, model_output='raw', feature_perturbation='tree_path_dependent')[source]
Instantiate a SHAP
shap.TreeExplainerfor a fitted random forest classifier.- Parameters
clf (RandomForestClassifier) – A fitted sklearn random forest classifier to explain.
data (Optional[np.ndarray]) – Background dataset used to estimate expected values. Required for
feature_perturbation='interventional'; ignored for'tree_path_dependent'. Default: None.model_output (str) – What the explainer attributes, e.g.
'raw','probability'or'log_loss'. Default: ‘raw’.feature_perturbation (str) – SHAP feature-perturbation method, either
'tree_path_dependent'or'interventional'. Default: ‘tree_path_dependent’.
- Returns
A SHAP tree explainer for the passed classifier.
- Return type
shap.TreeExplainer
- Example
>>> explainer = TrainModelMixin().define_tree_explainer(clf=clf)
- delete_other_annotation_columns(df, annotations_lst, raise_error=True)[source]
Helper to drop fields that contain annotations which are not the target.
- Parameters
df (pd.DataFrame) – Dataframe holding features and annotations.
annotations_lst (List[str]) – column fields to be removed from df
- Raise_error bool raise_error
If True, throw error if annotation column doesn’t exist. Else, skip. Default: True.
- Returns
Dataframe without non-target annotation columns
- Return type
pd.DataFrame
- Examples
>>> self.delete_other_annotation_columns(df=df, annotations_lst=['Sniffing'])
- dviz_classification_visualization(x_train, y_train, clf_name, class_names, save_dir)[source]
Helper to create visualization of example decision tree using dtreeviz.
- static find_collinear_features(data, threshold)[source]
Identify collinear features in a pandas DataFrame for removal.
Finds pairs of features with Pearson correlation coefficients above the specified threshold and returns the names of features that should be removed to reduce multicollinearity.
Serves as a validation wrapper around numba implementation.
See also
For the underlying numba-accelerated implementation, see
simba.mixins.train_model_mixin.TrainModelMixin.find_highly_correlated_fields()For non-numba statistical methods, seesimba.mixins.statistics_mixin.Statistics.find_collinear_features()EXPECTED RUNTIMES
FEATURES N
TIME (S)
100
1.0479
200
2.3715
400
6.1663
800
23.639
1600
160.69
ITERATIONS:3
Intel(R) Core(TM) i9-14900KF
OBSERVATION COUNT: 1M
- Parameters
data (pd.DataFrame) – Input DataFrame containing numeric features. Each column represents a feature and each row represents an observation. Must contain only numeric data types.
threshold (float) – Correlation threshold for identifying collinear features. Must be between 0.0 and 1.0. Higher values (e.g., 0.9) identify only very highly correlated features, while lower values (e.g., 0.1) identify more loosely correlated features.
- Returns
List of column names that are highly correlated with other features and should be considered for removal to reduce multicollinearity.
- Return type
List[str]
- Example
>>> a = np.random.randint(0, 5, (1_000_000, 100)) >>> df = pd.DataFrame(a) >>> c = find_collinear_features(data=df, threshold=0.0025)
Find highly correlated fields in a dataset using Pearson product-moment correlation coefficient.
Calculates the absolute correlation coefficients between columns in a given dataset and identifies pairs of columns that have a correlation coefficient greater than the specified threshold. For every pair of correlated features identified, the function returns the field name of one feature. These field names can later be dropped from the input data to reduce memory requirements and collinearity.
See also
For non-numba method, see
simba.mixins.statistics_mixin.Statistics.find_collinear_features(). For validation wrapper, seesimba.mixins.train_model_mixin.TrainModelMixin.find_collinear_features()- Parameters
data (np.ndarray) – Two dimension numpy array with features represented as columns and frames represented as rows.
threshold (float) – Threshold value for significant collinearity.
field_names (List[str]) – List mapping the column names in data to a field name. Use types.ListType(types.unicode_type) to take advantage of JIT compilation
- Returns
Unique field names that correlates with at least one other field above the threshold value.
- Return type
List[str]
- Example
>>> data = np.random.randint(0, 1000, (1000, 5000)).astype(np.float32) >>> field_names = [] >>> for i in range(data.shape[1]): field_names.append(f'Feature_{i+1}') >>> highly_correlated_fields = TrainModelMixin().find_highly_correlated_fields(data=data, field_names=typed.List(field_names), threshold=0.10)
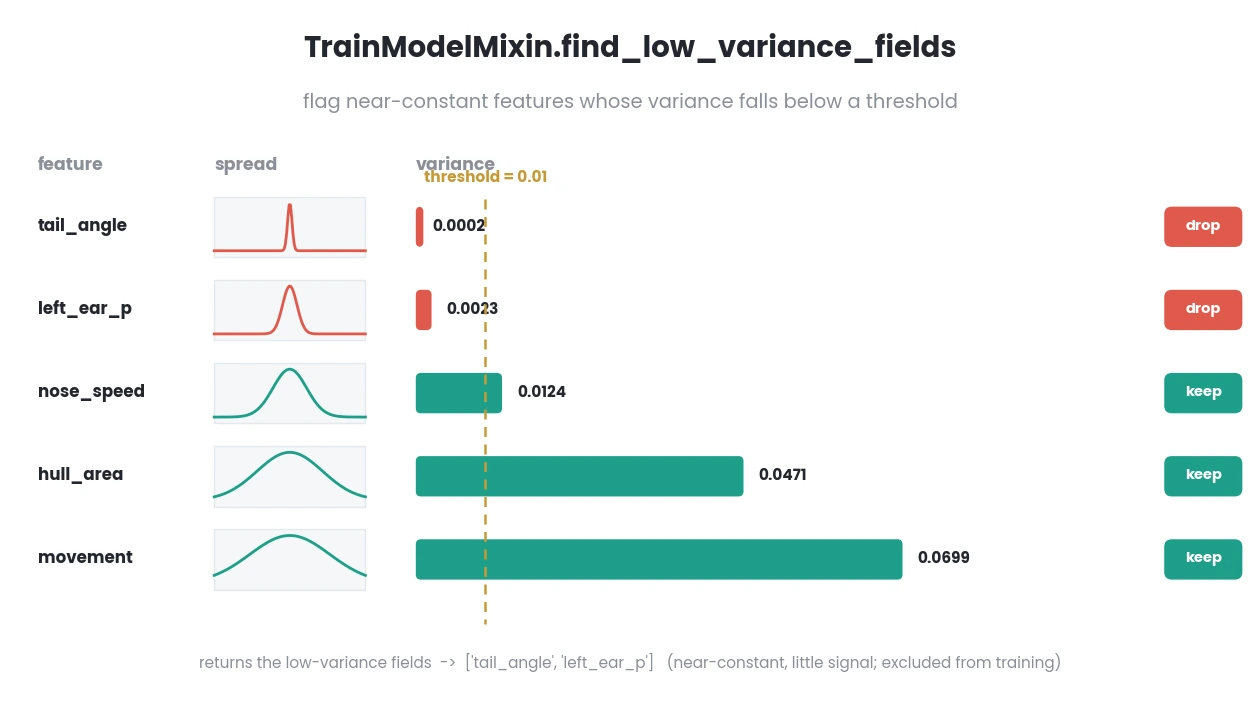
- static find_low_variance_fields(data, variance_threshold)[source]
Finds fields with variance below provided threshold.
- Parameters
data (pd.DataFrame) – Dataframe with continoues numerical features.
variance (float) – Variance threshold (0.0-1.0).
- Return List[str]
- static fit_scaler(scaler, data)[source]
Fit sklearn scaler to a 2D dataset, so it can later be used to transform data.
See also
To instantiate a scaler, see
simba.mixins.train_model_mixin.TrainModelMixin.define_scaler(). To transform data with the fitted scaler, seesimba.mixins.train_model_mixin.TrainModelMixin.scaler_transform().- Parameters
scaler (Union[MinMaxScaler, QuantileTransformer, StandardScaler]) – An un-fitted sklearn scaler object.
data (Union[pd.DataFrame, np.ndarray]) – The 2D numeric data to fit the scaler on. DataFrames are converted to their underlying values.
- Returns
The fitted scaler object.
- Return type
Union[MinMaxScaler, QuantileTransformer, StandardScaler]
- Example
>>> scaler = TrainModelMixin.define_scaler(scaler_name='min-max') >>> scaler = TrainModelMixin.fit_scaler(scaler=scaler, data=data)
- get_all_clf_names(config, target_cnt)[source]
Helper to get all classifier names in a SimBA project.
- Parameters
config (configparser.ConfigParser) – Parsed SimBA project_config.ini
target_cnt (int.ConfigParser) – Parsed SimBA project_config.ini
- Returns
All classifier names in project
- Return type
List[str]
- Example
>>> self.get_all_clf_names(config=config, target_cnt=2) >>> ['Attack', 'Sniffing']
- get_model_info(config, model_cnt)[source]
Helper to read in N SimBA random forest config meta files to python dict memory.
- Parameters
config (configparser.ConfigParser) – Parsed SimBA project_config.ini
model_cnt (int) – Count of models
- Return dict
Dictionary with integers as keys and hyperparameter dictionaries as keys.
- insert_column_headers_for_outlier_correction(data_df, new_headers, filepath)[source]
Helper to insert new column headers onto a dataframe following outlier correction.
- Parameters
data_df (pd.DataFrame) – Dataframe with headers to-be replaced.
filepath (str) – Path to where
data_dfis stored on disk.
- Param
DataFRame with the corrected headers following outlier correction.
- partial_dependence_calculator(clf, x_df, clf_name, save_dir, clf_cnt=None, grid_resolution=50, plot=True)[source]
Compute feature partial dependencies for every feature in training set.
- Parameters
clf (RandomForestClassifier) – Random forest classifier
x_df (pd.DataFrame) – Features training set
clf_name (str) – Name of classifier
save_dir (str) – Directory where to save the data
clf_cnt (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
- print_machine_model_information(model_dict)[source]
Helper to print model information in tabular form.
- Parameters
model_dict (dict) – dictionary holding model meta data in SimBA meta-config format.
- random_multiclass_bout_sampler(x_df, y_df, target_field, target_var, sampling_ratio, raise_error=False)[source]
Randomly sample multiclass behavioral bouts.
This function performs random sampling on a multiclass dataset to balance the class distribution. From each class, the function selects a count of “bouts” where the count is computed as a ratio of a user-specified class variable count. All bout observations in the user-specified class is selected.
- Parameters
x_df (pd.DataFrame) – A dataframe holding features.
y_df (pd.DataFrame) – A dataframe holding target.
target_field (str) – The name of the target column.
target_var (int) – The variable in the target that should serve as baseline. E.g.,
0if0represents no behavior.sampling_ratio (Union[float, dict]) – The ratio of target_var bout observations that should be sampled of non-target_var observations. E.g., if float
1.0, and there are 10` bouts of target_var observations in the dataset, then 10 bouts of each non-target_var observations will be sampled. If different under-sampling ratios for different class variables are needed, use dict with the class variable name as key and ratio relative to target_var as the value.raise_error (bool) – If True, then raises error if there are not enough observations of the non-target_var fullfilling the sampling_ratio. Else, takes all observations even though not enough to reach criterion.
- Raises
SamplingError – If any of the following conditions are met: - No bouts of the target class are detected in the data. - The target variable is present in the sampling ratio dictionary. - The sampling ratio dictionary contains non-integer keys or non-float values less than 0.0. - The variable specified in the sampling ratio is not present in the DataFrame. - The sampling ratio results in a sample size of zero or less. - The requested sample size exceeds the available data and raise_error is True.
- Return (pd.DataFrame, pd.DataFrame)
resampled features, and resampled associated target.
- Examples
>>> df = pd.read_csv('/Users/simon/Desktop/envs/troubleshooting/multilabel/project_folder/csv/targets_inserted/01.YC015YC016phase45-sample_sampler.csv', index_col=0) >>> undersampled_df = TrainModelMixin().random_multiclass_bout_sampler(data=df, target_field='syllable_class', target_var=0, sampling_ratio={1: 1.0, 2: 1, 3: 1}, raise_error=True)
- random_multiclass_frm_sampler(x_df, y_df, target_field, target_var, sampling_ratio, raise_error=False)[source]
Random multiclass undersampler.
This function performs random under-sampling on a multiclass dataset to balance the class distribution. From each class, the function selects a number of frames computed as a ratio relative to a user-specified class variable.
All the observations in the user-specified class is selected.
- Parameters
x_df (pd.DataFrame) – A dataframe holding features.
y_df (pd.DataFrame) – A dataframe holding target.
target_field (str) – The name of the target column.
target_var (int) – The variable in the target that should serve as baseline. E.g.,
0if0represents no behavior.sampling_ratio (Union[float, dict]) – The ratio of target_var observations that should be sampled of non-target_var observations. E.g., if float
1.0, and there are 10` target_var observations in the dataset, then 10 of each non-target_var observations will be sampled. If different under-sampling ratios for different class variables are needed, use dict with the class variable name as key and ratio raletive to target_var as the value.raise_error (bool) – If True, then raises error if there are not enough observations of the non-target_var fullfilling the sampling_ratio. Else, takes all observations even though not enough to reach criterion.
- Return (pd.DataFrame, pd.DataFrame)
resampled features, and resampled associated target.
- Examples
>>> df = pd.read_csv('/Users/simon/Desktop/envs/troubleshooting/multilabel/project_folder/csv/targets_inserted/01.YC015YC016phase45-sample_sampler.csv', index_col=0) >>> TrainModelMixin().random_multiclass_frm_sampler(data_df=df, target_field='syllable_class', target_var=0, sampling_ratio=0.20) >>> TrainModelMixin().random_multiclass_frm_sampler(data_df=df, target_field='syllable_class', target_var=0, sampling_ratio={1: 0.1, 2: 0.2, 3: 0.3})
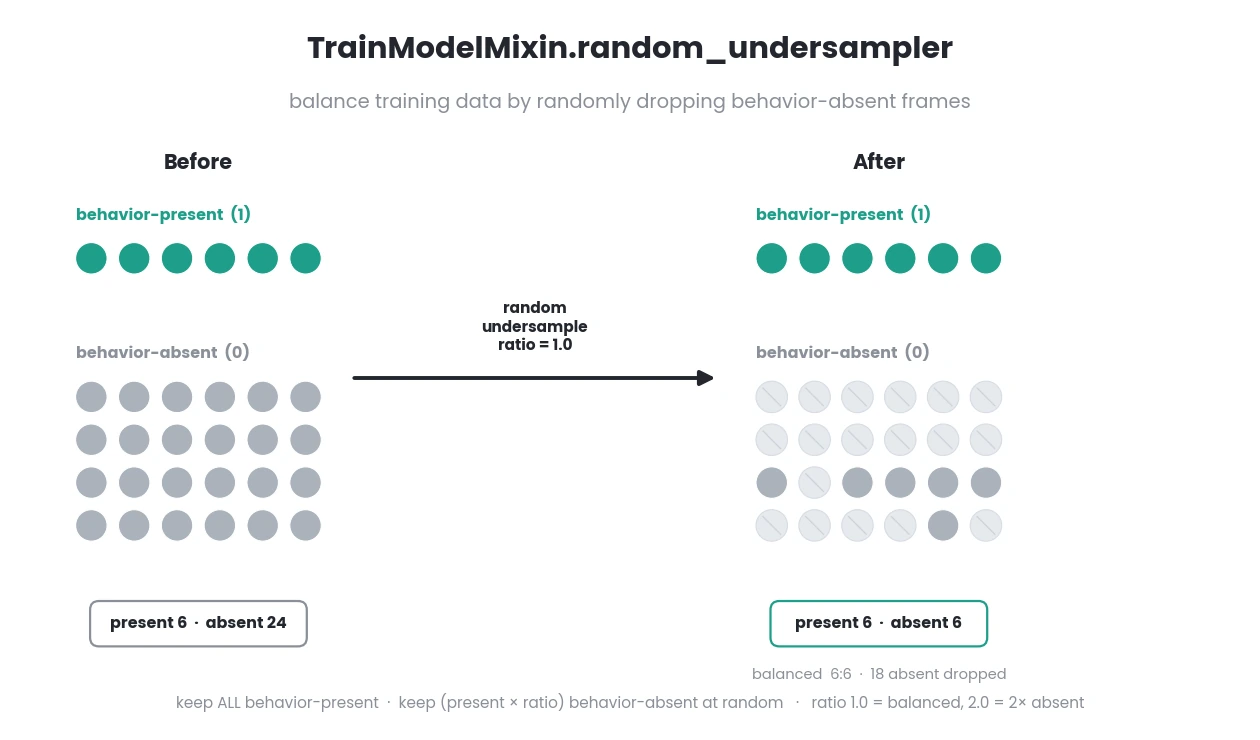
- random_undersampler(x_train, y_train, sample_ratio)[source]
Perform random under-sampling of behavior-absent frames in a dataframe.
- Parameters
x_train (np.ndarray) – 2-dimensional array representing the features in train set
y_train (np.ndarray) – Array representing the target in the training set.
sample_ratio (float) – Ratio of behavior-absent frames to keep relative to the behavior-present frames. E.g.,
1.0returns an equal count of behavior-absent and behavior-present frames.2.0returns twice as many behavior-absent frames as and behavior-present frames.
- Returns
Size-2 tuple with DataFrames representing the under-sampled feature set and under-sampled target set.
- Return type
Tuple[pd.DataFrame, pd.DataFrame]
- Examples
>>> self.random_undersampler(x_train=x_train, y_train=y_train, sample_ratio=1.0)
- read_all_files_in_folder(file_paths, file_type, classifier_names=None, raise_bool_clf_error=True)[source]
Read in all data files in a folder into a single pd.DataFrame.
Note
For improved runtime using multiprocessing and pyarrow, use
read_all_files_in_folder_mp()For improved runtime using ``concurrent` library, usesimba.mixins.train_model_mixin.TrainModelMixin.read_all_files_in_folder_mp_futures().- Parameters
file_paths (List[str]) – List of file paths representing files to be read in.
file_type (str) – The type of files to be read in (e.g., csv)
classifier_names (Optional[List[str]]) – Optional list of classifier names representing fields of human annotations. If not None, then assert that classifier names are present in each data file.
- Returns
concatenated DataFrame if all data represented in
file_paths, and a aligned list of frame numbers associated with the rows in the DataFrame.- Return type
Tuple[pd.DataFrame, List[int]]
- Examples
>>> self.read_all_files_in_folder(file_paths=['targets_inserted/Video_1.csv', 'targets_inserted/Video_2.csv'], file_type='csv', classifier_names=['Attack'])
- static read_all_files_in_folder_mp(file_paths, file_type, classifier_names=None, raise_bool_clf_error=True)[source]
Multiprocessing helper function to read in all data files in a folder to a single pd.DataFrame for downstream ML. Defaults to ceil(CPU COUNT / 2) cores. Asserts that all classifiers have annotation fields present in each dataframe.
Note
If multiprocess fail, reverts to
simba.mixins.train_model_mixin.read_all_files_in_folder()See also
For single process method, use
read_all_files_in_folder()For concurrent library, usesimba.mixins.train_model_mixin.TrainModelMixin.read_all_files_in_folder_mp_futures().- Parameters
annotations_file_paths (List[str]) – List of file-paths
file_type (List[str]) – The filetype of
file_pathsOPTIONS: csv or parquet.classifier_names (Optional[List[str]]) – List of classifier names representing fields of human annotations. If not None, then assert that classifier names are present in each data file.
- Returns
concatenated DataFrame if all data represented in
file_paths, and an aligned list of frame numbers associated with the rows in the DataFrame.- Return type
Tuple[pd.DataFrame, List[int]]
- read_all_files_in_folder_mp_futures(annotations_file_paths, file_type, classifier_names=None, raise_bool_clf_error=True)[source]
Multiprocessing helper function to read in all data files in a folder to a single pd.DataFrame for downstream ML through
concurrent.Futures. Asserts that all classifiers have annotation fields present in each dataframe.Note
A
concurrent.Futuresalternative tosimba.mixins.train_model_mixin.read_all_files_in_folder_mp()which has usesmultiprocessing.ProcessPoolExecutorand reported unstable on Linux machines.If multiprocess failure, reverts to
simba.mixins.train_model_mixin.read_all_files_in_folder()See also
For single process method, use
read_all_files_in_folder()For improved runtime using multiprocessing and pyarrow, useread_all_files_in_folder_mp()- Parameters
file_paths (List[str]) – List of file-paths
file_type (List[str]) – The filetype of
file_pathsOPTIONS: csv or parquet.classifier_names (Optional[List[str]]) – List of classifier names representing fields of human annotations. If not None, then assert that classifier names are present in each data file.
raise_bool_clf_error (bool) – If True, raises an error if a classifier column contains values outside 0 and 1.
- Returns
concatenated DataFrame if all data represented in
file_paths, and an aligned list of frame numbers associated with the rows in the DataFrame.- Return type
Tuple[pd.DataFrame, List[int]]
- read_in_all_model_names_to_remove(config, model_cnt, clf_name)[source]
Helper to find all field names that are annotations but are not the target.
- Parameters
config (configparser.ConfigParser) – Configparser object holding data from the project_config.ini
model_cnt (int) – Number of classifiers in the SimBA project
clf_name (str) – Name of the classifier.
- Returns
List of non-target annotation column names.
- Return type
List[str]
- Examples
>>> self.read_in_all_model_names_to_remove(config=config, model_cnt=2, clf_name=['Attack'])
- read_pickle(file_path)[source]
Read pickled RandomForestClassifier object.
- Parameters
file_path (Union[str, os.PathLike]) – Path to pickle file on disk.
- Returns
A scikitRandomForestClassifier object.
- Return type
RandomForestClassifier
- save_rf_model(rf_clf, clf_name, save_dir, save_file_no=None)[source]
Helper to save pickled classifier object to disk.
See also
To write pickle, can also use
write_pickle()To read pickle, seeread_pickle()orread_pickle().- Parameters
rf_clf (RandomForestClassifier) – sklearn random forest classifier
clf_name (str) – Classifier name
save_dir (str) – Directory where to save output as pickle.
save_file_no (Optional[int]) – If integer, represents the count of the classifier within a grid search. If none, the classifier is not part of a grid search.
- Returns
None. Results are saved in
save_dir.
- static scaler_transform(data, scaler, name='')[source]
Transform a dataframe using a previously fitted sklearn scaler.
See also
To instantiate a scaler, see
simba.mixins.train_model_mixin.TrainModelMixin.define_scaler(). To fit a scaler, seesimba.mixins.train_model_mixin.TrainModelMixin.fit_scaler().- Parameters
data (pd.DataFrame) – The data to transform.
scaler (Union[MinMaxScaler, StandardScaler, QuantileTransformer]) – A previously fitted sklearn scaler.
name (Optional[str]) – Optional scaler name used in the error message when the feature count mismatches. Default: “”.
- Raises
FeatureNumberMismatchError – If
datahas a different number of columns than the scaler was fitted on.- Returns
The transformed data, with original column names and index preserved.
- Return type
pd.DataFrame
- Example
>>> scaler = TrainModelMixin.define_scaler(scaler_name='min-max') >>> scaler = TrainModelMixin.fit_scaler(scaler=scaler, data=data) >>> transformed = TrainModelMixin.scaler_transform(data=data, scaler=scaler)
- smote_oversampler(x_train, y_train, sample_ratio)[source]
Helper to perform SMOTE oversampling of behavior-present annotations.
- Parameters
x_train (np.ndarray) – Features in train set
y_train (np.ndarray) – Target in train set
sample_ratio (float) – Over-sampling ratio
- Returns
Size-2 tuple arrays representing the over-sampled feature set and over-sampled target set.
- Return type
Tuple[np.ndarray, np.ndarray]
- Examples
>>> self.smote_oversampler(x_train=x_train, y_train=y_train, sample_ratio=1.0)
- smoteen_oversampler(x_train, y_train, sample_ratio)[source]
Helper to perform SMOTEEN oversampling of behavior-present annotations.
- Parameters
x_train (np.ndarray) – Features in train set
y_train (np.ndarray) – Target in train set
sample_ratio (float) – Over-sampling ratio
- Returns
Size-2 tuple arrays representing the over-sampled feature set and over-sampled target set.
- Return type
Tuple[np.ndarray, np.ndarray]
- Examples
>>> self.smoteen_oversampler(x_train=x_train, y_train=y_train, sample_ratio=1.0)
- static split_and_group_df(df, splits, include_split_order=True)[source]
Helper to split a dataframe for multiprocessing. If include_split_order, then include the group number in split data as a column. Returns split data and approximations of number of observations per split.
- split_df_to_x_y(df, clf_name)[source]
Helper to split dataframe into features and target.
- Parameters
df (pd.DataFrame) – Dataframe holding features and annotations.
clf_name (str) – Name of target.
- Returns
Size-2 tuple containing two dataframes - the features, and the target.
- Return type
Tuple[pd.DataFrame, pd.DataFrame]
- Examples
>>> self.split_df_to_x_y(df=df, clf_name='Attack')
Batch random forest inference
- class simba.model.inference_batch.InferenceBatch(config_path, features_dir=None, save_dir=None, minimum_bout_length=None, feature_subsets_by_clf=None, model_dict=None, save_agg_stats=None, verbose=True)[source]
Run classifier inference on all files with the
project_folder/csv/features_extracteddirectory. Results are stored in theproject_folder/csv/machine_resultsdirectory of the SimBA project.Note
To compute aggregate statistics from the output of this class, see
simba.data_processors.agg_clf_calculator.AggregateClfCalculator()- Parameters
config_path (Union[str, os.PathLike]) – path to SimBA project config file in Configparser format.
features_dir (Optional[Union[str, os.PathLike]]) – Optional directory containing featurized files in CSV or parquet format. If None, then the project_folder/csv/features_extracted directory of the project will be used.
save_dir (Optional[Union[str, os.PathLike]]) – Optional directory to save the data for the analyzed videos. If None, then the project_folder/csv/machine_results directory of the project will be used.
minimum_bout_length (Optional[int]) – Optional minimum bout length (milliseconds) override. If None, classifier-specific minimum bout settings from project configuration are used.
feature_subsets_by_clf (Optional[Dict[str, Dict[str, List[str]]]]) – Optional per-classifier feature subsets to use during inference. Format:
{classifier_name: {subset_name: [feature_col_1, feature_col_2, ...]}}. If provided, each classifier is applied once per subset and outputs are suffixed with the subset name.model_dict (Optional[Dict[str, Dict[str, Union[str, int, float]]]]) – Optional override of the classifiers to run. Format:
{model_name: {'model_path': '/path/to/clf.sav', 'minimum_bout_length': 100, 'threshold': 0.5}}. If None, classifier definitions are read from the project config (current behavior). When provided, these models replace the project-config classifiers for this run.save_agg_stats (Optional[Union[str, os.PathLike]]) – Optional directory in which to save aggregate classifier statistics. If None, no aggregate statistics are computed. If a directory is provided,
simba.data_processors.agg_clf_calculator.AggregateClfCalculatoris run after inference completes, reading from this class’ssave_dirand writing its CSV outputs tosave_agg_stats.verbose (bool) – If True, print progress and status messages during inference. Default: True.
- Example I
>>> inferencer = InferenceBatch(config_path='MyConfigPath') >>> inferencer.run()
- Example II
>>> inferencer = InferenceBatch(config_path=r"D:/troubleshooting/mitra/project_folder/project_config.ini", features_dir=r"D:/troubleshooting/mitra/project_folder/videos/bg_removed/rotated/tail_features/APPENDED") >>> inferencer.run()
Batch multi-animal random forest inference
- class simba.model.inference_multi_animal_batch.InferenceMultiAnimalBatch(config_path, clf_name)[source]
Run a single trained behavior classifier across every animal in a SimBA project, producing per-animal predictions in the output CSVs.
See also
Training counterpart:
simba.model.grid_search_rf.GridSearchRandomForestClassifierwithfeature_subset_suffix='_animal_<N>'.- Parameters
config_path (Union[str, os.PathLike]) – Path to the SimBA project_config.ini.
clf_name (str) – Name of the configured classifier to run multi-animal inference for.
- Example
>>> InferenceMultiAnimalBatch(config_path=r'/path/project_folder/project_config.ini', clf_name='wing_wave').run()
Batch multi-class random forest inference
Grid-search random forest classifiers
- class simba.model.grid_search_rf.GridSearchRandomForestClassifier(config_path, feature_subset_suffix=None, target_dir=None, save_dir=None)[source]
Train one or more random-forest classifiers from SimBA meta-config files.
Reads model hyperparameters and sampling settings from meta files in
project_folder/configsand trains one model per valid meta file. Training data is loaded from annotated target files and saved models plus evaluation artifacts are written to the configured output directory.Note
Searches the SimBA project
project_folder/configsdirectory for meta files and builds one model per valid config file. Tutorial.- Parameters
config_path (Union[str, os.PathLike]) – Path to SimBA project config file in ConfigParser format.
feature_subset_suffix (Optional[str]) – Optional suffix used to subset feature columns before training. If set, only feature columns ending with this suffix are retained.
target_dir (Optional[Union[str, os.PathLike]]) – Optional directory with annotated target files (CSV or parquet, matching project file type). If None, project default targets directory is used.
save_dir (Optional[Union[str, os.PathLike]]) – Optional directory where trained models and evaluation artifacts are saved. If None, defaults to
<model_dir>/validationsfrom project configuration.
- Example
>>> _ = GridSearchRandomForestClassifier(config_path='MyConfigPath').run()
Grid-search random forest multi-classifiers
Random forest inference - validation
- class simba.model.inference_validation.InferenceValidation(config_path, input_file_path, clf_path)[source]
Run a single classifier on a single featurized input file. Results are saved within the
project_folder/csv/validationdirectory of the SimBA project by defau- Parameters
Note
- Example
>>> InferenceValidation(config_path=r"MyProjectConfigPath", input_file_path=r"FeatureFilePath", clf_path=r"ClassifierPath")
Fit random forest classifier
- class simba.model.train_rf.TrainRandomForestClassifier(config_path)[source]
Train a single random forest model using hyperparameter setting and evaluation methods stored within the SimBA project config .ini file (
global environment).- Parameters
config_path (Union[str, os.PathLike]) – path to SimBA project config file in Configparser format
Note
- Example
>>> model_trainer = TrainRandomForestClassifier(config_path='MyConfigPath') >>> model_trainer.run() >>> model_trainer.save()
Fit random forest classifier - multi-class
Ordinal classifier methods
- class simba.model.ordinal_clf.OrdinalClassifier[source]
This class implements a strategy for ordinal classification by fitting multiple binary classifiers to predict thresholds between classes.
It is particularly useful for problems where the target variable has an inherent order but uneven intervals between levels. Thi includes human severity scores, for example, seizures, stereotopy, convulsion, bizarre behavior scores ranging fro 0-5.
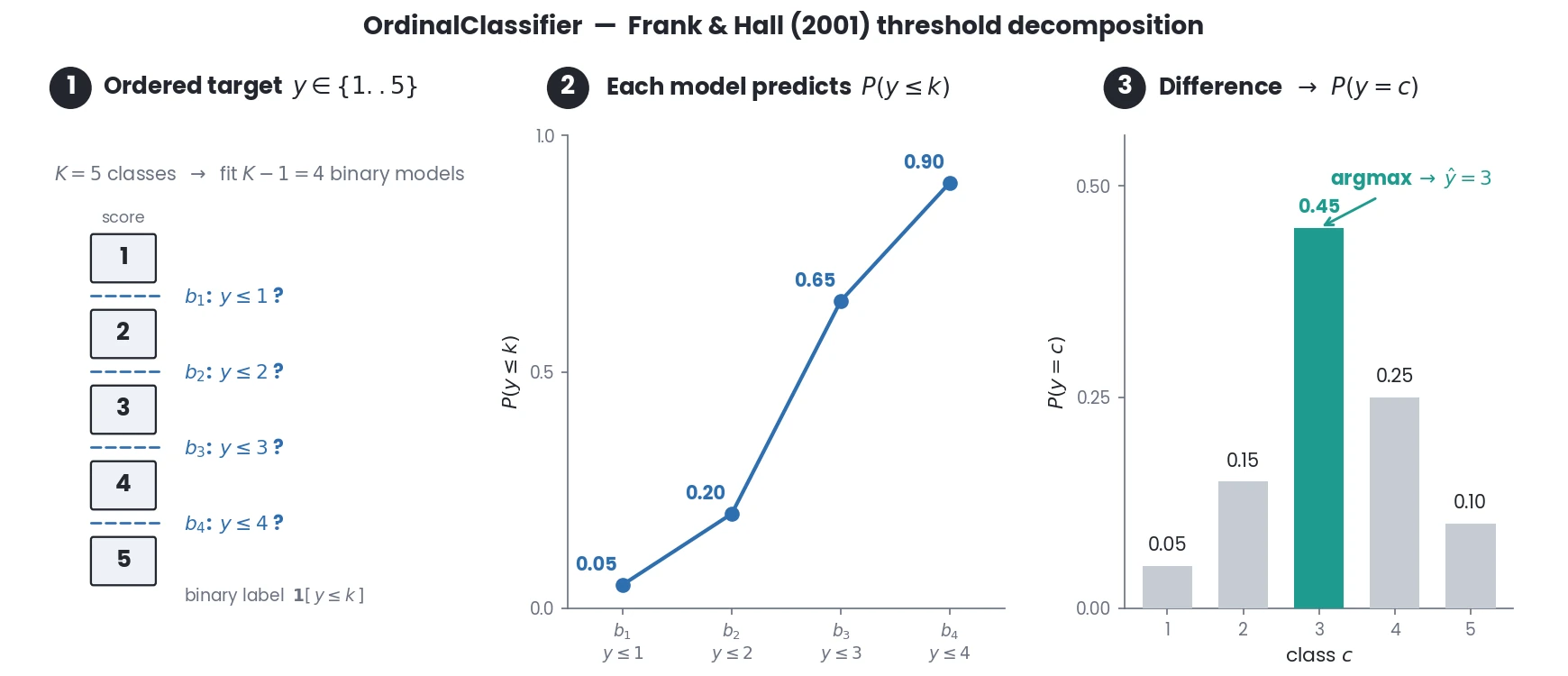
For an ordered target with \(K\) classes,
simba.model.ordinal_clf.OrdinalClassifier.fit()trains \(K-1\) binary classifiers, where model \(b_k\) predicts the cumulative probability \(P(y \leq k)\).simba.model.ordinal_clf.OrdinalClassifier.predict_proba()recovers the per-class probabilities by differencing the padded cumulative vector \([\,0,\;P(y \leq k),\;1\,]\), andsimba.model.ordinal_clf.OrdinalClassifier.predict()returns theirargmax.Warning
If larger data sizes (>2m) pass a GPU
cuml.ensemble.RandomForestClassifierobject.Note
References
- 1
Frank, Eibe, and Mark Hall. “A Simple Approach to Ordinal Classification.” In Machine Learning: ECML 2001, edited by Luc De Raedt and Peter Flach, 2167:145–56. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2001. https://doi.org/10.1007/3-540-44795-4_13.
- 2
Sabnis, Gautam, Leinani Hession, J. Matthew Mahoney, Arie Mobley, Marina Santos, and Vivek Kumar. “Visual Detection of Seizures in Mice Using Supervised Machine Learning,” May 31, 2024. https://doi.org/10.1101/2024.05.29.596520.
- 3
Another implementation / benchmarking by Lee Prevost - https://github.com/leeprevost/OrdinalClassifier/tree/main.
- 4
- 5
Wurm, M. J., Rathouz, P. J., & Hanlon, B. M. (2021). Regularized ordinal regression and the ordinalNet R package. Journal of Statistical Software, 99(6).
- Example
>>> X = np.random.randint(0, 500, (100, 50)) >>> y = np.random.randint(1, 6, (100)) >>> rf_mdl = TrainModelMixin().clf_define(cuda=False) >>> fitted_mdl = OrdinalClassifier.fit(X, y, rf_mdl, -1) >>> y_hat = OrdinalClassifier.predict_proba(X, fitted_mdl) >>> y = OrdinalClassifier.predict(X, fitted_mdl) >>> save_path = r"/mnt/c/Users/sroni/Downloads/Box4-20191208T1639-1652/ord_mdl/mdl.pickle" >>> OrdinalClassifier.save(mdl=fitted_mdl, save_path=save_path) >>> rf_mdl = OrdinalClassifier.load(file_path=save_path) >>> y_hat = OrdinalClassifier.predict_proba(X, rf_mdl)
Regression - metrics
- simba.model.regression.metrics.mean_absolute_error(y_true, y_pred, weights=None)[source]
Compute the Mean Absolute Error (MAE) between the true and predicted values.
- Parameters
y_true (np.ndarray) – A 1D array of true values (ground truth).
y_pred (np.ndarray) – A 1D array of predicted values.
weights (np.ndarray) – An optional 1D array of weights for each observation. If provided, the weighted MAE is computed.
- Returns
The Mean Absolute Error (MAE) as a float. A lower value indicates a better fit.
- Return type
- simba.model.regression.metrics.mean_absolute_percentage_error(y_true, y_pred, epsilon=1e-10, weights=None)[source]
Compute the Mean Absolute Percentage Error (MAPE)
- Parameters
y_true (np.ndarray) – The array containing the true values (dependent variable) of the dataset. Should be a 1D numeric array of shape (n,).
y_pred (np.ndarray) – The array containing the predicted values for the dataset. Should be a 1D numeric array of shape (n,) and of the same length as y_true.
epsilon (float) – A small pseudovalue to replace zeros in y_true to avoid division by zero errors.
weights (Optional[np.ndarray]) – An optional 1D array of weights to apply to each error. If provided, the weighted mean absolute percentage error is computed.
- Returns
The Mean Absolute Percentage Error (MAPE) as a float, in percentage format. A lower value indicates better prediction accuracy.
- Return type
- Example
>>> x, y = np.random.random(size=(100000,)), np.random.random(size=(100000,)) >>> mean_absolute_percentage_error(y_true=x, y_pred=y)
- simba.model.regression.metrics.mean_squared_error(y_true, y_pred, weights=None)[source]
Compute the Mean Squared Error (MSE) between the true and predicted values.
- Parameters
y_true (np.ndarray) – The array containing the true values (dependent variable) of the dataset. Should be a 1D numeric array of shape (n,).
y_pred (np.ndarray) – The array containing the predicted values for the dataset. Should be a 1D numeric array of shape (n,) and of the same length as y_true.
weights (Optional[np.ndarray]) – An optional 1D array of weights to apply to each squared error. If provided, the weighted mean squared error is computed.
- Returns
The Mean Squared Error (MSE) as a float. A lower value indicates better model accuracy.
- Return type
- simba.model.regression.metrics.r2_score(y_true, y_pred, weights=None)[source]
Compute the R^2 (coefficient of determination) score.
- Parameters
y_true (np.ndarray) – 1D array of true values (dependent variable).
y_pred (np.ndarray) – 1D array of predicted values, same length as y_true.
weights (np.ndarray) – Optional 1D array of weights for each observation.
- Returns
The R^2 score as a float. A value closer to 1 indicates better fit.
- Return type
- simba.model.regression.metrics.root_mean_squared_error(y_true, y_pred, weights=None)[source]
Compute the Root Mean Squared Error (RMSE) between the true and predicted values.
- Parameters
y_true (np.ndarray) – The array containing the true values (dependent variable) of the dataset. Should be a 1D numeric array of shape (n,).
y_pred (np.ndarray) – The array containing the predicted values for the dataset. Should be a 1D numeric array of shape (n,) and of the same length as y_true.
weights (Optional[np.ndarray]) – An optional 1D array of weights to apply to each squared error. If provided, the weighted mean squared error is computed.
- Returns
The Root Mean Squared Error (MSE) as a float. A lower value indicates better model accuracy.
- Return type
Regression - fit and transform
- simba.model.regression.model.evaluate_xgb(y_pred, y_true, metrics, stratified=False)[source]
Evaluates the performance of a regression model (e.g., XGBoost) by calculating selected metrics. Optionally, the evaluation can be stratified by unique values in the true target variable (y_true), where performance is computed separately for each class/level.
- Parameters
y_pred (np.ndarray) – Predicted values generated by the model, must have the same shape as y_true.
y_true (np.ndarray) – True target values to compare the predictions against.
metrics (List[str]) – List of metrics to compute.
stratified – If True, computes the metric for each unique class/level in y_true. If False (default), computes the metric for the entire dataset.
- Returns
A dictionary containing the computed metrics.
- Return type
- Example
>>> x = pd.DataFrame(np.random.randint(0, 500, (100, 20))) >>> y = np.random.randint(1, 6, (100,)) >>> mdl = fit_xgb(x=x, y=y) >>> new_x = pd.DataFrame(np.random.randint(0, 500, (100, 20))) >>> y_pred = transform_xgb(x=new_x, mdl=mdl) >>> evaluate_xgb(y_pred=y_pred, y_true=y, metrics=['MAE', 'MAPE', 'RMSE', 'MSE'])
- simba.model.regression.model.fit_xgb(x, y, mdl)[source]
Fits an XGBoost regressor model to the given data.
- Parameters
x (pd.DataFrame) – Input feature matrix where each row represents a sample and each column a feature. The data must have numeric types.
y (np.ndarray) – Target values, must be a 1-dimensional array of numeric types with the same number of rows as x.
mdl (xgb.XGBRegressor) – Defined xgb.XGBRegressor. E.g., can be defined with
simba.model.regression.model.xgb_define(),
- Returns
Trained XGBoost regressor model.
- Return type
xgb.XGBRegressor
- Example
>>> x = pd.DataFrame(np.random.randint(0, 500, (100, 20))) >>> y = np.random.randint(1, 6, (100,)) >>> mdl = fit_xgb(x=x, y=y)
- simba.model.regression.model.transform_xgb(x, mdl)[source]
Transforms the input data using the provided XGBoost model by making predictions.
- Parameters
x (pd.DataFrame) – Input feature matrix where each row represents a sample and each column a feature. The data must have numeric types.
mdl (xgb.XGBRegressor) – Trained XGBoost model to use for making predictions.
- Returns
Predictions rounded to 2 decimal places.
- Return type
np.ndarray
- Example
>>> x, y = pd.DataFrame(np.random.randint(0, 500, (100, 20))), np.random.randint(1, 6, (100,)) >>> mdl = fit_xgb(x=x, y=y) >>> new_x = pd.DataFrame(np.random.randint(0, 500, (100, 20))) >>> results = transform_xgb(x=new_x, mdl=mdl)
- Example
>>> x, y = pd.DataFrame(np.random.randint(0, 500, (100, 20))), np.random.randint(1, 6, (100,)) >>> mdl = fit_xgb(x=x, y=y) >>> new_x = pd.DataFrame(np.random.randint(0, 500, (100, 20))) >>> results = transform_xgb(x=new_x, mdl=mdl)
- simba.model.regression.model.xgb_define(objective='reg:squarederror', n_estimators=100, max_depth=6, verbosity=1, learning_rate=0.3, eta=0.3, gamma=0.0, tree_method='auto')[source]
Defines an XGBoost regressor.
- Parameters
objective (str) – The learning objective for the model.
n_estimators (int) – Number of boosting rounds. Must be greater than or equal to 1. Default is 100.
max_depth (int) – Maximum depth of a tree. Increasing this value makes the model more complex and more likely to overfit. Must be greater than or equal to 1. Default is 6.
verbosity (int) – Verbosity of the training process (0-3).
learning_rate (float) – Step size shrinkage used to prevent overfitting. Lower values make the model more robust but require more boosting rounds. Must be between 0.1 and 1.0. Default is 0.3.
eta (float) – Learning rate alias. Must be between 0.0 and 1.0. Default is 0.3.
gamma (float) – Minimum loss reduction required to make a further partition on a leaf node of the tree. Larger values prevent overfitting. Must be greater than or equal to 0.0. Default is 0.0.
tree_method (str) – The tree construction algorithm used in XGBoost.
- Returns
An initialized XGBoost Regressor with the specified configuration.
- Return type
xgb.XGBRegressor
SAM2 segmentation inference
- class simba.model.sam_inference.SamInference(video_path, weights_path, save_dir, prompts, labels, names, imgsz=1024, confidence=0.25, vertice_cnt=100)[source]
- Example
>>> i = SamInference(video_path=r"MyVideo", >>> labels=[[1]], >>> prompts=[[166, 428]], >>> weights_path=r"D:\yolo_weights\sam2.1_b.pt", >>> save_dir=r'C: roubleshooting\sam_results', >>> names=('Animal1',)) >>> i.run()
Fit YOLO model
- class simba.model.yolo_fit.FitYolo(model_yaml, save_path, weights_path=None, epochs=200, batch=16, plots=True, imgsz=640, format=None, device=0, verbose=True, workers=8, patience=500, cache=False, device_id=None)[source]
Fit an Ultralytics YOLO model (detection, pose, or segmentation) from SimBA projects with parameter validation.
Note
Works with any Ultralytics model flavour (bbox, pose, segmentation).
Download starter weights from HuggingFace.
See also
simba.bounding_box_tools.yolo.utils.fit_yolo()for the functional API.simba.bounding_box_tools.yolo.utils.load_yolo_model()to load trained weights. For instructions, see YOLO Pose Estimation Training Documentation.- Parameters
weights_path (Union[str, os.PathLike]) – Path to base weights (e.g.,
yolo11n.ptor.onnxexport).model_yaml (Union[str, os.PathLike]) – Dataset configuration YAML describing dataset folders and class labels.
save_path (Union[str, os.PathLike]) – Directory where training outputs (weights, metrics, plots) are written.
epochs (int) – Training epochs to run. Must be ≥ 1. Default
200.batch (Union[int, float]) – Batch size per step. Default
16.plots (bool) – If
True, Ultralytics saves training curves. DefaultTrue.imgsz (int) – Square image resolution used during training. Default
640.format (Optional[str]) – Optional weights format override. Must belong to
simba.utils.enums.Options.VALID_YOLO_FORMATS. DefaultNone.device (Union[Literal['cpu'], int]) – Compute device string or CUDA index. Default
0.verbose (bool) – Emit detailed progress information. Default
True.workers (int) – Data-loader worker processes. Use
-1for all cores. Default8.patience (int) – Early-stopping patience (epochs without improvement). Default
100.cache (Union[bool, Literal['disk']]) – Image caching strategy.
Truecaches all dataset images in RAM on the first epoch so subsequent epochs read from memory instead of disk (fastest, requires the dataset to fit in RAM)."disk"caches decoded images as.npyfiles on disk (avoids re-decoding each epoch without needing the dataset to fit in RAM, but uses more disk space).Falsedisables caching. DefaultFalse.
- Raises
SimBAGPUError – If no CUDA-capable GPU is detected.
SimBAPAckageVersionError – If
ultralyticsis unavailable in the environment.FileNotFoundError – If
weights_pathormodel_yamldo not exist.ValueError – If provided arguments fail SimBA validation checks.
- Example
>>> fitter = FitYolo( ... weights_path=r"D:\yolo_weights\yolo11n-pose.pt", ... model_yaml=r"D:\datasets\pose_project\map.yaml", ... save_path=r"D:\datasets\pose_project\mdl", ... epochs=300, ... batch=24, ... device=0, ... imgsz=640, ... ) >>> fitter.run()
YOLO bounding-box inference
- class simba.model.yolo_inference.YoloInference(weights, video_path, verbose=False, save_dir=None, half_precision=True, device=0, batch_size=400, core_cnt=8, threshold=0.25, max_detections=300, max_per_class=None, smoothing_method=None, smoothing_time_window=None, interpolate=False, imgsz=320, bbox_size=None, stream=True)[source]
Performs object detection inference on a video using a YOLO model.
YOLO-based object detection (bounding-box) on one or more video files. It supports GPU acceleration, batch processing, streaming, and optional result saving. The model returns bounding box coordinates and class confidence scores for each frame. Results can be smoothed or interpolated to handle detection gaps.
See also
To perform bounding box and keypoint (pose) detection, see
YOLOPoseInference(). To perform keypoint (pose) detection with tracking, seeYOLOPoseTrackInference()To visualize bounding boxes only, seeYOLOVisualizer()EXPECTED RUNTIMES
VIDEOS (COUNT)
FRAMES (COUNT)
TIME (S)
STDEV(S)
1
9000
19.69
0.185202592
2
18000
39.91333333
0.718424202
3
27000
59.20333333
0.29143324
4
36000
80.82
1.407870733
BATCH SIZE: 500
IMGSZ: 256
NVIDIA GeForce RTX 4070
CPU COUNT (LOADERS): 16
3 runs
- Parameters
weights (Union[str, os.PathLike, YOLO]) – Path to YOLO model weights or a preloaded
ultralytics.YOLOmodel instance.video_path (Union[Union[str, os.PathLike], List[Union[str, os.PathLike]]]) – Input video path, list of paths, or directory containing videos.
verbose (Optional[bool]) – If True, print progress information.
save_dir (Optional[Union[str, os.PathLike]]) – Directory to save output CSV files. If None, results are returned in-memory.
half_precision (Optional[bool]) – If True, run inference in fp16 where supported.
device (Union[Literal['cpu'], int]) – Inference device (‘cpu’ or CUDA index).
batch_size (Optional[int]) – Number of frames per prediction batch.
core_cnt (int) – CPU thread count used by torch.
threshold (float) – Detection confidence threshold in [0.0, 1.0].
max_detections (int) – Maximum detections per frame (total, across all classes) returned by the model.
max_per_class (Optional[int]) – Maximum number of detections to retain per class per frame. E.g., if one ‘resident’ and one ‘intruder’ is expected, set this to 1. Defaults to None, meaning all detected instances of each class are retained (up to
max_detections).smoothing_method (Optional[Literal['savitzky-golay', 'bartlett', 'blackman', 'boxcar', 'cosine', 'gaussian', 'hamming', 'exponential']]) – Optional temporal smoothing method for bbox coordinates.
smoothing_time_window (Optional[int]) – Smoothing window in milliseconds. Used only when
smoothing_methodis not None.interpolate (bool) – If True, interpolate missing bbox coordinates (nearest, per class).
imgsz (int) – Model inference image size.
bbox_size (Optional[Tuple[int, int]]) – Optional fixed bbox size
(height, width)in pixels applied to detected boxes.stream (Optional[bool]) – If True, use streaming predictions.
- Returns
If
save_diris None, returns a dict mapping video name to result dataframe. Otherwise saves CSVs and returns None.- Return type
Union[None, Dict[str, pd.DataFrame]]
- Example
>>> video_path = "/mnt/d/netholabs/yolo_videos/input/mp4_20250606083508/2025-05-28_19-50-23.mp4" >>> i = YoloInference( ... weights=r"/mnt/c/troubleshooting/coco_data/mdl/train8/weights/best.pt", ... video_path=video_path, ... save_dir=r"/mnt/c/troubleshooting/coco_data/mdl/results", ... verbose=True, ... device=0, ... interpolate=True, ... bbox_size=(128, 128) ... ) >>> i.run()